#include<iostream> #include<algorithm> #include<cstring> #include<cstdio> namespace BigInteger { #define maxn 10005 using std::sprintf; using std::string; using std::max; using std::istream; using std::ostream;
structBig_integer{ int d[maxn], len; voidclean() { while(len > 1 && !d[len-1]) len--; } Big_integer() { memset(d, 0, sizeof(d)); len = 1; } Big_integer(int num) { *this = num; } Big_integer(char* num) { *this = num; } Big_integer operator = (constchar* num){ memset(d, 0, sizeof(d)); len = strlen(num); for(int i = 0; i < len; i++) d[i] = num[len-1-i] - '0'; clean(); return *this; } Big_integer operator = (int num){ char s[10005]; sprintf(s, "%d", num); *this = s; return *this; } Big_integer operator + (const Big_integer& b){ Big_integer c = *this; int i; for (i = 0; i < b.len; i++){ c.d[i] += b.d[i]; if (c.d[i] > 9) c.d[i]%=10, c.d[i+1]++; } while (c.d[i] > 9) c.d[i++]%=10, c.d[i]++; c.len = max(len, b.len); if (c.d[i] && c.len <= i) c.len = i+1; return c; } Big_integer operator - (const Big_integer& b){ Big_integer c = *this; int i; for (i = 0; i < b.len; i++){ c.d[i] -= b.d[i]; if (c.d[i] < 0) c.d[i]+=10, c.d[i+1]--; } while (c.d[i] < 0) c.d[i++]+=10, c.d[i]--; c.clean(); return c; } Big_integer operator * (const Big_integer& b)const{ int i, j; Big_integer c; c.len = len + b.len; for(j = 0; j < b.len; j++) for(i = 0; i < len; i++) c.d[i+j] += d[i] * b.d[j]; for(i = 0; i < c.len-1; i++) c.d[i+1] += c.d[i]/10, c.d[i] %= 10; c.clean(); return c; } Big_integer operator / (const Big_integer& b){ int i, j; Big_integer c = *this, a = 0; for (i = len - 1; i >= 0; i--) { a = a*10 + d[i]; for (j = 0; j < 10; j++) if (a < b*(j+1)) break; c.d[i] = j; a = a - b*j; } c.clean(); return c; } Big_integer operator % (const Big_integer& b){ int i, j; Big_integer a = 0; for (i = len - 1; i >= 0; i--) { a = a*10 + d[i]; for (j = 0; j < 10; j++) if (a < b*(j+1)) break; a = a - b*j; } return a; } Big_integer operator += (const Big_integer& b){ *this = *this + b; return *this; } booloperator <(const Big_integer& b) const{ if(len != b.len) return len < b.len; for(int i = len-1; i >= 0; i--) if(d[i] != b.d[i]) return d[i] < b.d[i]; returnfalse; } booloperator >(const Big_integer& b) const{return b < *this;} booloperator<=(const Big_integer& b) const{return !(b < *this);} booloperator>=(const Big_integer& b) const{return !(*this < b);} booloperator!=(const Big_integer& b) const{return b < *this || *this < b;} booloperator==(const Big_integer& b) const{return !(b < *this) && !(b > *this);} string str()const{ char s[maxn]={}; for(int i = 0; i < len; i++) s[len-1-i] = d[i]+'0'; return s; } }; istream& operator >> (istream& in, Big_integer& x) { string s; in >> s; x = s.c_str(); return in; } ostream& operator << (ostream& out, const Big_integer& x) { out << x.str(); return out; } } usingnamespace BigInteger; usingnamespace std; structuse { Big_integer a; int num; booloperator < (const use &x)const { return a < x.a; } }; use data[21]; intmain() { int cnt; scanf("%d", & cnt); for (int i = 1; i <= cnt; ++i) cin >> data[i - 1].a, data[i - 1].num = i; sort(data, data + cnt); printf("%d\n", data[cnt - 1].num), cout << data[cnt - 1].a; return0; }
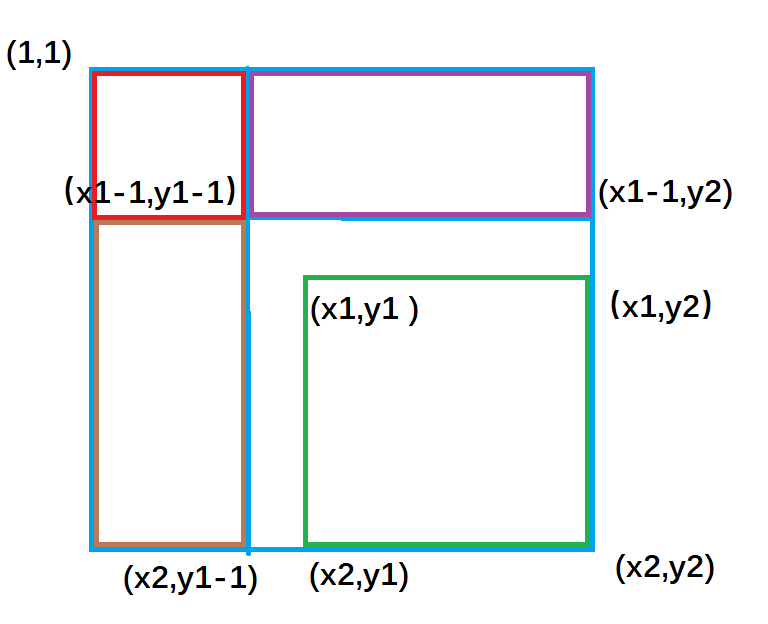
#include<iostream> usingnamespace std; constint N = 100010; int n, m; int a[N], s[N]; intmain() { ios::sync_with_stdio(false), cin.tie(0), cout.tie(0); cin >> n >> m; for (int i = 1; i <= n; i++)s[i] = s[i - 1] + a[i]; while (m--) { int l, r; cin >> l >> r; cout << s[r] - s[l - 1]; } return0; }
")




